

Pages
Avantages

Lundi matin, 8h47.
Tu ouvres ton inbox avec ton café encore trop chaud.
Objet : Your AWS Invoice for January 2026
Tu cliques. 12 847$.
Le mois passé? 8 200$.
Le mois d'avant? 7 650$.
Qu’est-ce qui s’est passé?
Tu scrolles à travers les lignes de facturation. EC2, RDS, Lambda, S3, CloudWatch… Des mots que tu ne comprends pas.
Tu te dis : "On n’a pas changé grand-chose pourtant."
Erreur.
Ton infra cloud, c'est comme un organisme vivant. Ça bouge tout le temps. Une feature ajoutée par-ci, une intégration testée par-là, un nouveau environnement de staging, une lambda mal configurée qui tourne 24/7 pour rien.
Y'a un nom pour ce problème-là :
FinOps.
Non, c'est pas juste un autre buzzword pour vendre des services. C'est littéralement la différence entre brûler ton cash ou l’utiliser intelligemment. Une seule lambda mal configurée peut te coûter 38 000$ USD par année… ça te donne une idée.
Dans ce case study, on décortique le FinOps avec Éric Pinet, président @ Unicorne.
Let's go 👇
Unicorne, c'est :
Ils ont créé Stable, leur SaaS de FinOps inspiré par les 5 erreurs qu'ils n'arrêtaient pas de voir dans les startups québécoises.
Définition simple:
FinOps = Financial Operations pour le cloud.
En gros : comment gérer tes coûts cloud de manière intelligente au lieu de te faire saigner à blanc chaque mois.
Le problème :
Le cloud, c'est pay-as-you-go. Tu paies juste ce que tu utilises. Ça sonne parfait, right?
Sauf que dans la vraie vie, tu contrôles pas vraiment ce que tu utilises.
Résultat : dérapages de coûts, surprises de facturation, ressources qui tournent 24/7 pour rien.
Exemple concret :
Tu lances un environnement de test vendredi après-midi. Tu oublies de le shut down. Il roule toute la fin de semaine. Lundi matin, t'as brûlé 600$ pour rien.
Multiplie ça par toutes les petites erreurs de config, les ressources orphelines, les commitments que tu prends pas... pis boom, tu te ramasses avec des factures qui font mal.
L'autre jour, je jasais avec Éric, et il m'a sorti l'analogie parfaite :
"Est-ce que tu gères ta sécurité une fois par année? Non. Pour être sécuritaire, il faut que tu scannes en continu ce qui se passe dans ton infrastructure. Le FinOps, c'est la même affaire."
Ton infra cloud, c'est pas statique. C'est vivant. Ça bouge tout le temps :
À chaque changement = risque de perdre de l’argent.
Si tu regardes tes coûts juste une fois par année (ou pire, jamais), tu te ramasses avec des milliers de dollars évaporés que t'aurais pu sauver.
Le FinOps, c'est pas une initiative one-shot. C'est un processus continu. Comme la sécurité, comme les tests, comme le monitoring.
Éric l'a dit dans notre capsule :
"Les 5 choses que les entreprises oublient ou ont de la difficulté à contrôler, c'est toujours les mêmes. Il y a des ressources dans le cloud qui sont peu utilisées, ils ont une mauvaise configuration, ils ne prennent pas leurs commitments, ils ont des extended support, ou ils font un mauvais rightsizing."
Décortiquons ces 5 choses une par une.
La plus fréquente. La plus facile à corriger.
Y'a des outils natifs dans AWS qui te permettent d'identifier ça assez facilement.
Exemples concrets :
Tu continues de payer pour tout ça. Chaque mois. Pour rien.
L'analogie Netflix :
C'est comme si tu payais pour Netflix Unlimited, mais tu te connectes pas pendant 3 mois. Netflix pourrait techniquement te dire "Yo, ça serait vraiment le fun si tu prenais le plus petit forfait ou si tu mettais ton abonnement sur pause."
Mais Netflix a zéro avantage à faire ça pour ses clients. AWS non plus.
C'est ta responsabilité.
Ça, ça fait mal.
Le rightsizing, c'est ajuster la taille de tes ressources en fonction de ce que t'as vraiment besoin.
Le problème :
Souvent, on over-provisionne par peur de manquer de jus. Ou on sous-provisionne pis on se ramasse avec des problèmes de performance.
Un exemple :
Éric m'a raconté un cas de client qui avait 500 lambdas. Une seule — UNE SEULE — était mal configurée en quantité de mémoire.
Coût annuel de cette erreur : 38 000$ US.
Pour une lambda.
Imagine si t'en as 10, voir des centaines demal configurées.
AKA tu laisses de l'argent sur la table.
AWS te dit : "Engage-toi à utiliser cette ressource pendant 1 an, je te donne -30% de rabais. Engage-toi 3 ans, je te donne encore plus."
La peur :
"Ouais mais je l'utiliserai peut-être pas 3 ans. Ça serait poche de m'engager pour rien."
Le calcul :
Quand tu fais les maths, tu sauves tellement d'argent en prenant le commitment que, rendu après ~14 mois, t'es déjà breakeven.
Même si tu changes d'idée après, tu perds pas d'argent.
Mais les gens ont peur de s'engager, alors ils payent le plein prix.
Coûts supplémentaires pour des versions obsolètes de logiciels ou services.
T'utilises une vieille version de MySQL? Tu payes un supplément pour le support étendu.
Souvent oublié dans les calculs initiaux, mais ça s'accumule.
Ça, c'est le catch-all.
Ton architecture est juste... pas optimale dès le départ.
Exemples :
Chaque petite sub-optimisation s'additionne. Et rendu à la fin du mois, ça fait mal.
En 2024-2025, l'arrivée des LLM a complètement changé le FinOps.
Pourquoi? Parce qu'on a une nouvelle manière de facturer.
Avant, tu payais pour du compute (CPU, RAM, storage). Assez simple.
Maintenant avec les LLM, tu paies au token.
Mais c'est pas aussi simple :
Exemple concret :
AWS Bedrock te donne accès à une quinzaine de modèles différents :
Chaque modèle a sa propre structure de prix. Certains coûtent 10x plus cher que d'autres par token.
Le piège :
Tu fais ton proof of concept. Ça marche. Nice! Tu commences à scaler. Boom — tes coûts explosent parce que tu n'as pas optimisé ton utilisation de tokens.
1. Caching intelligent
Évite de reposer les mêmes questions au modèle. Cache les réponses fréquentes.
2. Summarization
Réduis ton context window. Au lieu d'envoyer un document de 10 000 tokens, résume-le en 500 tokens.
3. Model selection
Utilise le bon modèle pour la bonne tâche. Pas besoin d'un modèle ultra-puissant pour classifier du texte simple.
4. Guardrails
Tu veux pas que ton LLM réponde n'importe quoi hors de ton scope? Tu mets des guardrails.
Mais attention : les guardrails ajoutent des coûts en tokens supplémentaires. Faut trouver le bon balance.
"Comment tu vas maximiser tes profits avec ça? Plus ça va te coûter cher en token, moins tu vas faire d'argent. Le but, c'est d'optimiser ce que tu vas faire pour que ça te coûte le moins cher possible pour donner ton résultat."
Traduction :
Si ton SaaS roule sur des LLMs et que chaque requête te coûte 0.50$ en tokens, mais que ton client paye 20$ par mois... ça scale pas.
Faut optimiser avant de scaler.
Après avoir aidé des dizaines de clients avec les mêmes 5 problèmes, Éric et son équipe se sont dit :
"On fait ça en service, en manuel, tout le temps. Pourquoi on en ferait pas un produit?"
Ainsi est né Stable.

En une ligne :
Un SaaS de FinOps qui te donne une visibilité en temps réel sur tes coûts AWS et t'alerte avant que ça devienne un problème.
Conçu pour :
Ce que ça fait :
En gros :
Stable transforme tes données de facturation AWS — qui sont un bordel incompréhensible — en insights actionnables.
Au lieu de t'arracher les cheveux à essayer de comprendre pourquoi ta facture a explosée, tu vois exactement où ton argent s'en va.
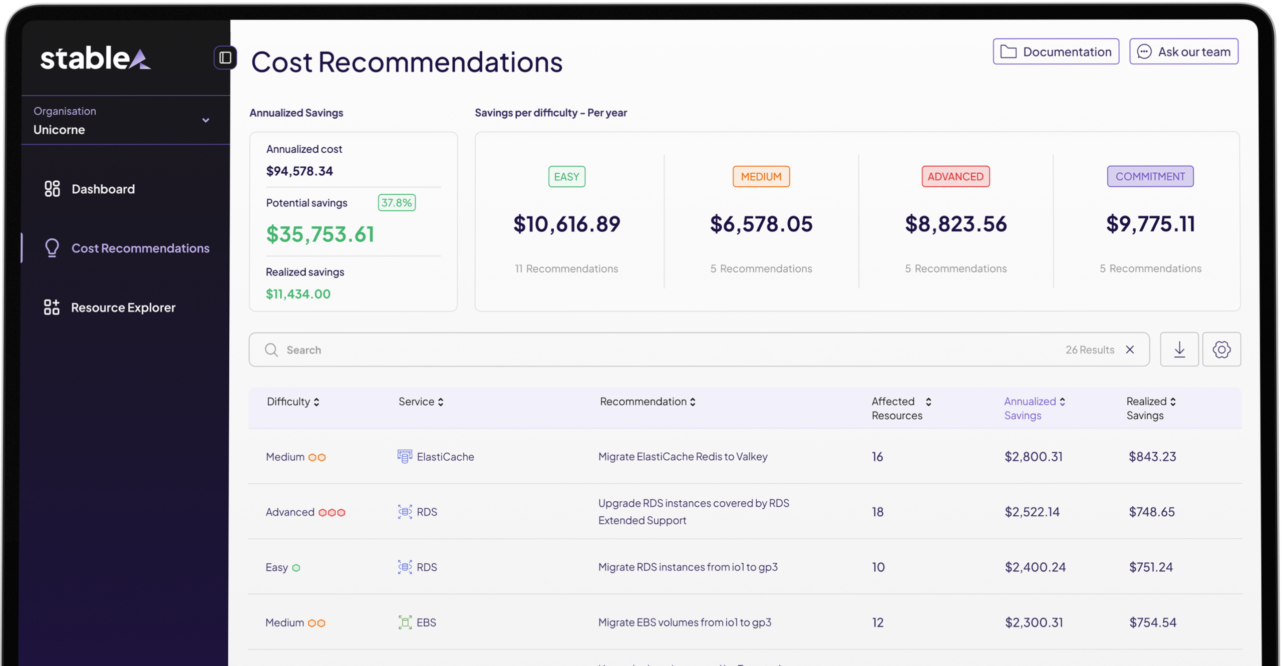
Le conseil #1 d'Éric :
"Mettre en place la première fondation, c'est avoir la visibilité sur ce que vous faites, puis des alertes pour quand ça dépasse vos prévisions puis vos budgets, que vous soyez avertis avant la facture à la fin du mois."
Concrètement :
Le FinOps, c'est pas un projet. C'est une pratique continue.
Ajoute-le dans :
Quand tu conçois un nouveau feature, pose-toi la question : "Ça va coûter combien en infra?"
Exactement comme tu te poses la question : "Ça va être sécuritaire?"
Le remboursement AWS :
"Quand vous faites des erreurs et que ça vous coûte plus cher que prévu, si vous ouvrez un ticket de support à AWS avant que la facture soit rentrée à la fin du mois, vous avez plus de chances que ce soit facile de vous faire rembourser."
En gros, si tu te rends compte le 15 du mois que t'as oublié de shutdown un environnement de staging qui a roulé non-stop pendant 2 semaines?
Ouvre un ticket de support tout de suite.
Explique la situation. Souvent, AWS va te créditer une bonne partie. Mais faut réagir vite.
Si tu attends de recevoir la facture, c'est beaucoup plus compliqué.
Au final, le FinOps, c'est pas du rocket science.
C'est juste avoir la discipline de :
Si tu te reconnais dans les 5 erreurs mentionnées plus haut, t'es pas tout seul. Littéralement toutes les startups passent par là.
La différence entre celles qui scalent et celles qui brûlent leur cash? Elles prennent le FinOps au sérieux et elles arrêtent de payer pour des ressources qu'elles utilisent même pas.
Le ROI est évident :
Si Stable ou une consultation avec Unicorne te coûte 5K$ et te sauve 40K$... c'est un no-brainer.
📚 Ressources utiles :
Capsule précédente : AWS — Sauve des milliers $ sans tout casser
Épisode 126 du pod : Toute l'histoire d'Éric et Unicorne
Unicorne : partenaire Unicorne
Stable : site web
LinkedIn : Eric Pinet pour le poker directement
On a un excellent formulaire pour ajouter votre excellent SaaS sur le site. Essayez ça!
Updates sur le podcast, la cie, les events IRL. Contenu premium pour les abonnés SaaSpal — éditorial de Frank, Q&A, roadmap du pod.